You’ve probably heard about multi-armed bandit testing as an alternative to traditional A/B tests. The appeal is obvious: why keep sending half your traffic to a losing variation when you could be converting more visitors right now?
But multi-armed bandit testing isn’t always the better choice. This guide breaks down when to use it and how to get reliable results.
Multi-Armed Bandit Testing Overview
The term multi-armed bandit (MAB) comes from the world of slot machines, which are nicknamed one-armed bandits for the lever on the side and their tendency to take your money.
In statistics and machine learning, the “multi-armed bandit problem” asks a simple question: when you don’t know the outcomes, how can you make the best decisions over time?
Imagine standing in front of several slot machines, each with different but unknown payouts. You can only play one at a time. Do you keep pulling the lever on the machine that seems to be paying out the most, or do you risk trying others to see if one might be even better?
That’s the core idea of the multi-armed bandit problem: how do you balance exploitation (sticking with what’s working) and exploration (testing new options that could perform better)?
This is the same logic that drives multi-armed bandit testing on a website. Instead of slot machines, you have page or element variations. The system constantly evaluates which one is performing best and adjusts traffic automatically to exploit high performers while still exploring other versions enough to keep learning.
How multi-armed bandit testing works
You begin the same way you’d start an A/B test, by creating the variations you want to test. Maybe you’re testing different headlines on your landing page, new call-to-action buttons, or completely different layouts.
After building these variations, you decide what you want to measure (e.g. clicks, sign-ups, purchases), and hit launch.
That’s it. From there, the algorithm takes over.
At the start of the test, the algorithm doesn’t know which version of your page will perform best, so it splits traffic evenly across all your variations. As visitors interact with each variation and your testing tool collects conversion data, the MAB algorithm begins to shift the balance of traffic towards the variation that is performing better.
Say Version B is converting at 5% while Version A is only converting at 3%. The algorithm shifts more traffic toward the winner.
Instead of keeping the split at 50/50 for the duration of the test (as happens in A/B testing), the MAB algorithm might move to 70/30, sending more visitors to the better-performing page.
From there, the algorithm continuously monitors performance. If Version B keeps winning, its traffic share keeps growing to maybe 80%, then 90%.
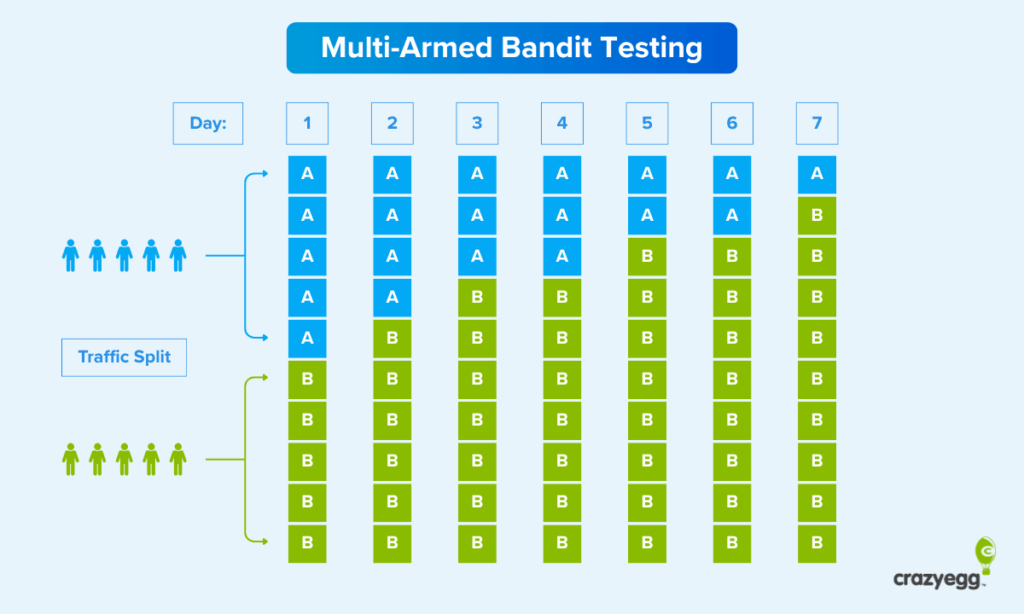
But if Version A suddenly starts performing better, the system notices and adjusts the traffic split again.
It’s constantly rebalancing based on what’s actually working right now.
Unlike classic A/B tests that have a static traffic allocation, multi-armed bandit tests keep adapting based on the new data coming in.
But even when one variation is clearly winning and getting 95% of traffic, that remaining 5% going to other versions serves a purpose. Maybe visitor preferences will change. Maybe that losing variation will suddenly work better with a different audience segment. The system is always balancing “try new things” with “do what works.”
The major benefit is that you’re not waiting weeks for statistical significance. With multi-armed bandit testing, you’re minimizing losses and maximizing conversions from day one.
The math behind the magic
When you are using a platform to run MAB testing, all of the math and complex statistical calculations are running behind the curtain, so to speak. You just see the results.
What’s actually happening is that the testing platform is using one of several approaches to decide how to allocate new traffic as it comes in. Most approaches fall into several categories:
- Bayesian: continuously updates probabilities as new data arrives, giving each variation a constantly refined estimate of success.
- Upper Confidence Bound (UCB): makes decisions based on how confident the system is in each variation’s performance, exploring less as certainty grows.
- ε-greedy: keeps sending most traffic to the top performer while occasionally testing others to stay open to surprises. (ε is the Greek letter for epsilon, so you may see this called epsilon-greedy)
Most testing tools don’t share the formulas they use, and from the perspective of a marketer or CRO expert, it’s not critical to know. What matters is the speed with which you get to a productive result.
All of these approaches enable the testing platform to learn and adapt as new data comes in. Traffic shifts to different variations automatically based on these formulas to send more website visitors to the variations that are performing better.
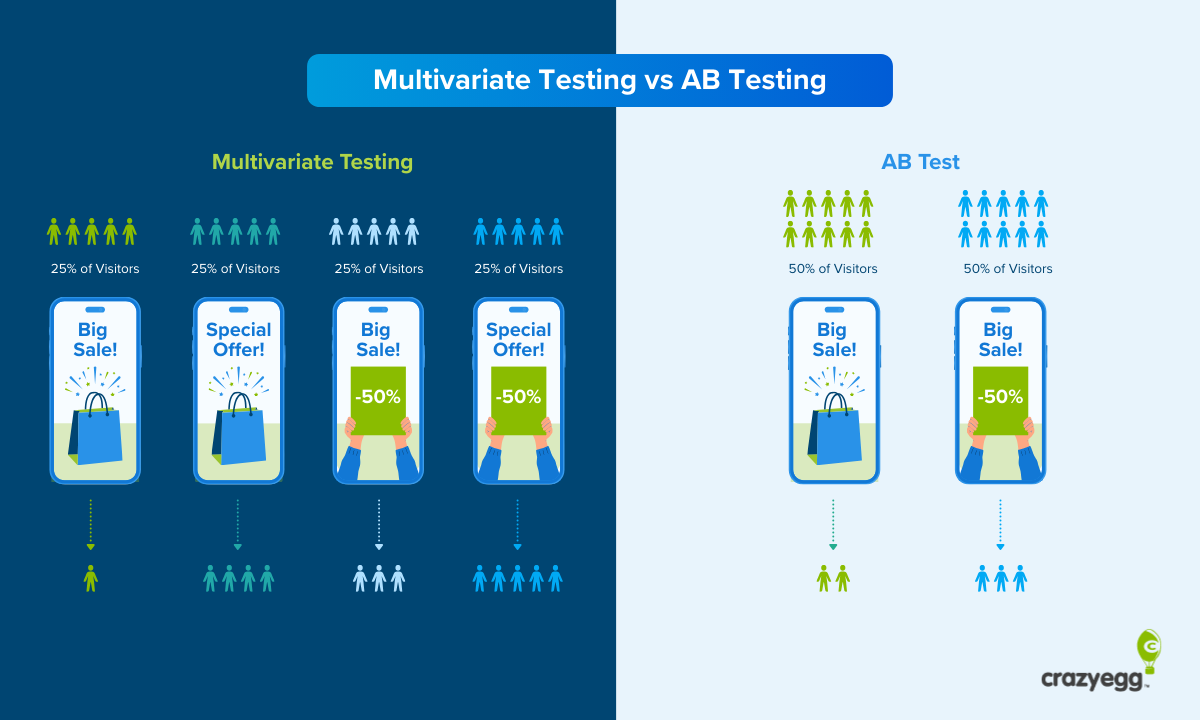
Multi-Armed Bandit vs. A/B Testing
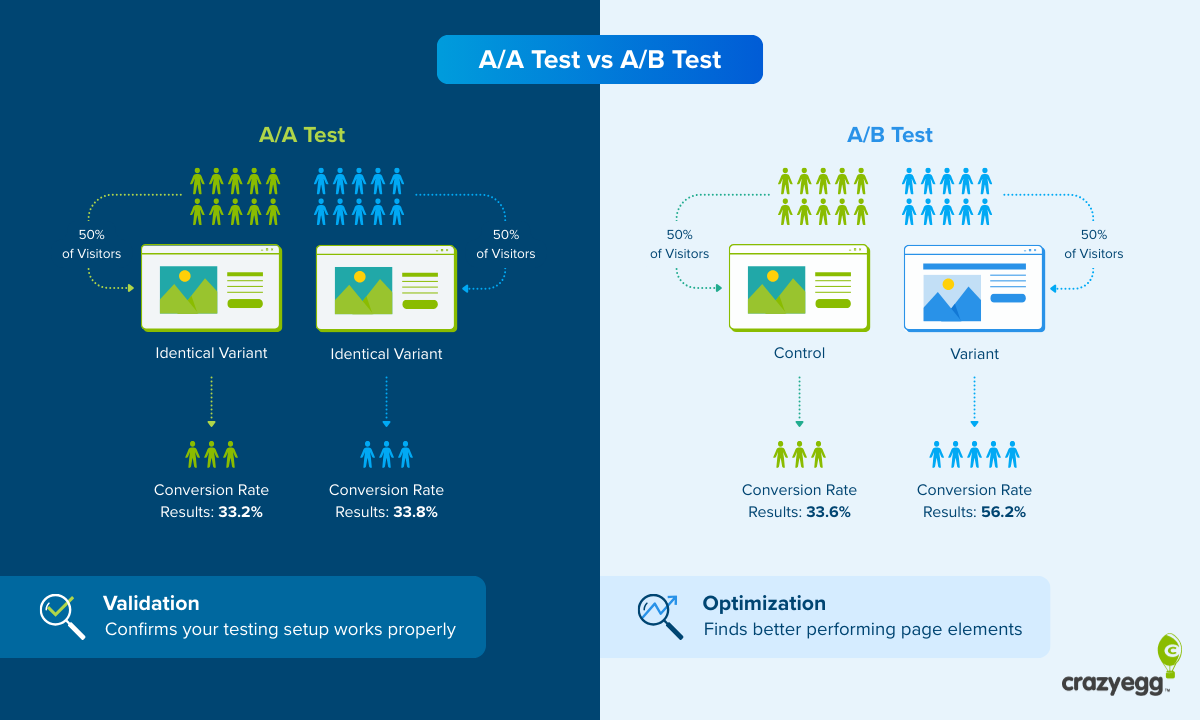
In a classic A/B test, you split traffic evenly between two versions of a web page and wait until you’ve gathered enough data to declare a winner. The two versions are identical except for a single change, which means you can know whether or not that change influences the website KPI you care about.
A/B testing is a controlled experiment. It’s designed to give you clear, reliable data that you can trust and replicate.
Multi-armed bandit testing, on the other hand, starts adjusting traffic allocation in real time to send more visitors to the version that’s performing better. Because of this, it cannot give you the same level of statistical certainty as A/B testing.
Here’s a quick comparison of the two types:
| Classic A/B Testing | Multi-Armed Bandit Testing |
|---|---|
| Splits traffic evenly throughout | Shifts traffic toward winners in real time |
| Maximizes statistical certainty | Maximizes conversions during the test |
| Best for proving cause and effect | Best for minimizing losses |
| Higher cost of testing (more losers shown) | Lower cost of testing (fewer losers shown) |
Both of these testing methods are very useful, but for different reasons. The multi-armed bandit approach is optimized for making money during the test, while classic A/B testing is optimized for learning with certainty.
The essential tradeoff is that multi-armed bandit testing accepts a bit less certainty in exchange for better performance while you’re still testing.
For example, if you run a traditional A/B test for 2 weeks, and version B is clearly better by day 3, then you’re still sending half your traffic to the inferior version A for another 11 days.
Yes, the traditional A/B test will give you a much higher degree of statistical certainty that version B is better than version A, but at what cost?
Is the certainty worth sending 11 days of traffic to version A, which you can already tell is performing worse?
That’s 11 days of accepting fewer conversions than you otherwise would have had. That could mean fewer signups, fewer sales, and potentially a lot of lost revenue.
With MAB testing, the algorithm starts favoring Version B almost immediately, so you lose fewer conversions during the testing period.
When To Use Multi-Armed Bandit Testing
Multi-armed bandit testing is ideal when speed and performance matter more than statistical perfection.
Choose multi-armed bandit testing when:
- You want to minimize losses during testing. Every visitor who sees a poor-performing variation is a missed opportunity. MAB testing cuts those losses by shifting traffic toward winners quickly.
- You’re testing dramatically different variations. When the differences between versions are significant (a complete page redesign vs. the original, for example), a clear winner often emerges fast. Bandit testing capitalizes on that early signal.
- The cost of showing a poor variation is high. If you’re testing your checkout flow, pricing page, or signup form on a landing page, every lost conversion hurts. These high-stakes pages are perfect candidates for MAB testing because the algorithm protects your bottom line while it learns.
- You need to figure out the winner quickly. News sites testing headlines or ecommerce sites testing messaging for a flash are ideal scenarios. If time is tight and money is one the line, you will get a real material benefit from MAB testing’s rapid adaptation.
When Not To Use Multi-Armed Bandit Testing
There are some situations where the design of MAB testing is either too risky to use or unlikely to provide useful data for making smart decisions. In these cases, the rigor and statistical certainty of an A/B test is worth it.
Use A/B testing instead of MAB testing when:
- You need to understand why something won. If you’re testing to inform future strategy or learn about your target audience, you need clean data from a controlled experiment. MAB testing optimizes for results, not insights.
- Differences between variations are subtle. When you’re testing small tweaks (changing button text from “Buy Now” to “Add to Cart”), you need the full statistical power of an even traffic split. Subtle differences take longer to validate, and MAB testing’s early shifts might lead you astray.
- You’re reporting to stakeholders who expect traditional statistical significance. If your boss or your client wants to see confidence intervals and p-values, give them what they need. A/B testing delivers the documentation and certainty that satisfies rigorous review.
- You can afford to let a test run for a few weeks. If traffic isn’t a constraint and you’re not losing significant revenue by running a longer test, traditional A/B testing gives you rock-solid conclusions you can build on.
Tips for Using Multi-Armed Bandit Testing
Here are a few pointers for getting the most out of MAB testing on your site and validating the results.
1. Test metrics with a short feedback loop
MAB algorithms work best when conversions happen quickly after someone sees a variation. If there’s a long delay between viewing your page and converting (like in B2B sales cycles), the algorithm might shift traffic before it has accurate data.
For example, testing checkout flows and pricing pages with MAB makes sense because users convert (or don’t) in minutes.
Testing white paper downloads or free trial signups that lead to purchases 30-90 days later can be problematic. The MAB algorithm could easily start to favor a variation that gets immediate signups but fewer paid users down the line.
2. Expect early fluctuations
Although MAB testing can deliver results quicker than A/B tests, it’s important to let the test run long enough to gather a critical mass of data.
Early on, when the sample size is small, there is going to be a lot of volatility because the traffic is not being split evenly (as it would be during an A/B test). As the test gathers more data, you will see the statistical significance start to stabilize.
Don’t panic if you see wild swings in performance in the first few days of the test. That’s normal because the algorithm is shifting traffic based on minimal data. As the sample size goes up, the winning variation will emerge. Give it time.
3. Confirm important decisions with an A/B test
Because of its design, MAB testing is never going to deliver the same statistical certainty of A/B testing. For many situations, especially short-term campaigns, that tradeoff is worth it. But for major changes that will affect your site long-term, you might want additional validation.
Consider running MAB tests to minimize losses while you find wins quickly, and following up with an A/B test to confirm that the results are reliable.
This two-phase approach gives you the best of both worlds. You capture more conversions during the initial MAB phase, then you gain the statistical confidence you need to make a permanent change with the follow-up A/B test.
4. Validate results with one or several downstream metrics
It’s wise to track a few “quality” metrics to ensure that you are actually getting the results you want. There is always the possibility that the winning variation ends up getting customers who spend less, cancel orders, or churn quickly.
After all, a multi-armed bandit test is optimizing for a single metric, like signups. It has no way of knowing whether or not those signups are high quality or not.
Looking at average order value (AOV), refund rate, or customer lifetime value, can help a brand feel confident that they have found a variation that is likely to create more positive business outcomes.
5. Segment testing data
As with A/B testing, you can learn a lot by breaking the results down by traffic source, new vs. returning users, days of the week, time of day, and so on. Different groups of visitors often respond differently to the same changes you are testing.
For example, test results might show that mobile users convert higher for the control and desktop users convert higher for the variation. This is valuable information. It’s probably going to require additional rounds of testing to figure out why, and that’s a great opportunity.
By digging into the data, you can gather insights about your target market that can help you increase the conversion rate for different audience segments.
6. Keep external factors in mind
There is always a bit of randomness in conversions. Why people buy or sign up can be caused by many factors outside your control. To the extent possible, try to account for things like seasonality and competitor activity in your analysis of test results.
For example, if a competitor jacked up their price during the middle of your test, the increase you see in conversions may not be related to the variables you are testing on your site. It’s not always going to be as clear cut as this example, but in your analysis, try to rule out other possible causes for the results you see.
7. Use a testing platform
It’s certainly possible to build your own MAB testing system from the ground up, but it’s time-consuming and requires a number of specialists, like statisticians, data analysts, developers.
For companies with the resources, the payoff for creating your own system is that you will have a rich understanding of results and will likely be able to run more customized tests.
If you don’t have the resources, using a testing platform like Crazy Egg allows you to get up and running quickly. You won’t be able to customize your tests completely and you won’t be able to see the backend calculations.
Those downsides are acceptable to most marketers, who don’t want to spend months creating a new system to start testing their ideas.
The other huge benefit of using a testing platform is that they usually come with additional tools to help you analyze results. Want to segment the data for mobile and desktop users? That’s two clicks. In a custom built system, it’s likely to be a lot harder to do that kind of valuable analysis.
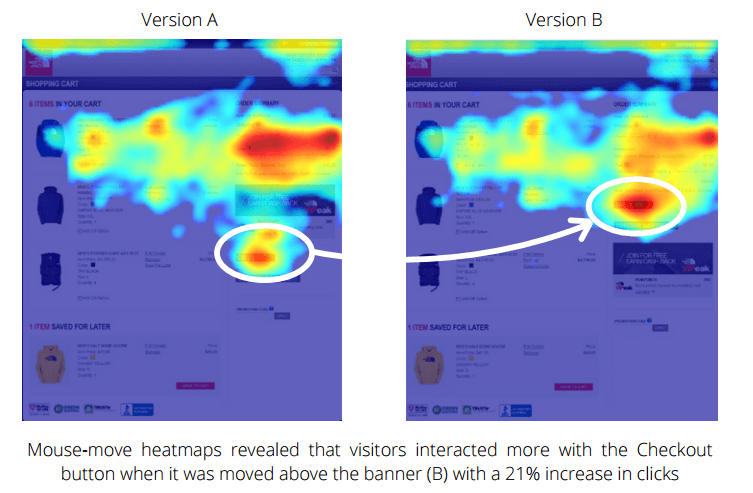
Crazy Egg, for example, also lets you look at how users in the test interacted with the site using website heatmaps, session recordings, and other tools. Insights about user preferences and behaviors gained from these tools can be as important as the test results themselves.